C标准库和实现
在系统调用和语言机制的基础上,libc 为我们提供了开发跨平台应用程序的 “第一级抽象”。在此基础上构建起了万千世界:C++ (扩充了 C 标准库)、Java、浏览器世界……今天,C 语言在应用开发方面有很多缺陷,但仍然为 “第一级抽象” 提供了一个有趣的范本:
libc简介
世界上 “最通用” 的高级语言库函数
- C 是一种 “高级汇编语言”
- 作为对比,C++ 更好用,但也更难移植
- 屏蔽了底层体系结构细节
- 管理数据、请求操作系统……
The C Standard Library
被很好地标准化
- ISO IEC 标准的一部分
- POSIX C Library 的子集
C 是 “高级汇编”,一定有为嵌入式设备实现的嵌入式的 libc。
musl libc
musl is an implementation of the C standard library built on top of the Linux system call API, including interfaces defined in the base language standard, POSIX, and widely agreed-upon extensions. musl is lightweight, fast, simple, free, and strives to be correct in the sense of standards-conformance and safety.
- Alpine Linux:采用 Musl + Busybox 的组合
AskGPT: How to compile a C program using musl as libc instead of glibc ?
musl-gcc- 试一试:从第一条指令开始调试一个 C 程序
libc 基本功能
基础数据的体系结构无关抽象
Freestanding 环境下也可以使用的定义
- stddef.h, stdint.h, stdbool.h, float.h, limits.h, stdarg.h(变长参数), inttype.h, math.h, setjmp.h
- 具体的API 见 clibrary/
字符串和数组操作
string.h:字符串/数组操作
- 标准库只对“标准库内部数据的”的线程安全性负责,例如
printf的 buffer; - 可以通过阅读源码/采用实验的形式验证
- 例如对 memset 采用多线程,可以验证其线程不安全;
libc 不得不在兼容性、性能等之间达到权衡
- 多线程共享的 API (例如文件操作、malloc/free 等) 需要上锁
memset/memcpy这类性能敏感的函数,则把消除数据竞争的任务交给了开发者
排序和查找
低情商 (低配置) API:C
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
void *bsearch(const void *key, const void *base,
size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
高情商 API:C++
操作系统对象与环境
stdio.h
FILE * 背后是个文件描述符,用 gdb 查看具体的 FILE *
- 封装了文件描述符上的系统调用 (fseek, fgetpos, ftell, feof, ...)
vprintf 系列
- 使用了
stdarg.h的参数列表
int vfprintf(FILE *stream, const char *format, va_list ap);
int vasprintf(char **ret, const char *format, va_list ap);
popen 和 pclose
FILE popen(const char command, const char *mode);
我们在游戏修改器中使用了它:但其是一个设计有缺陷的 API
- Since a pipe is by definition unidirectional, the type argument may specify only reading or writing, not both; the resulting stream is correspondingly read-only or write-only.
高情商 API (现代编程语言)
let dir_checksum = {
Exec::shell("find . -type f")
| Exec::cmd("sort") | Exec::cmd("sha1sum")
}.capture()?.stdout_str();
err, error, perror
所有 API 都可能失败:
man perror,
man 3 errno:线程私有变量,类似__thread修饰
errno:number of last error,如EACESS,ENOENT
environ
environ是谁进行赋值?
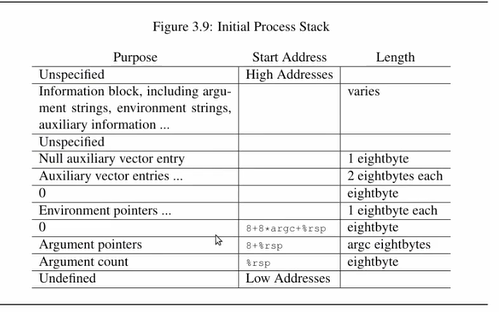
- RTFM: System V ABI
- p33:Figure 3.9 Initial Process Stack
- 操作系统:argc + argv + environ;
int main() {
extern char **environ;
for (char **env = environ; *env; env++) {
printf("%s\n", *env);
}
}
环境变量 extern char **environ的思考:通过对 musl 的 debug
- 程序的第一条指令执行时,
environ是没有进行赋值; - main 函数执行时,
environ已经被赋值; _start_c-->__libc_start_main-->__init_llibc;
操作系统给进程的初始状态:initial process stack(根据需求/场景搜索相关的权威手册)
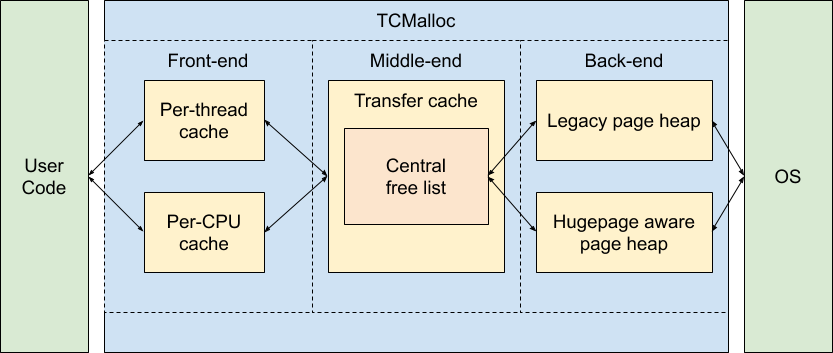
动态内存管理
如何分配一大段内存
- 用
MAP_ANONYMOUS申请,想多少就有多少,超过物理内存上限都行
反而,操作系统不支持分配一小段内存
- 这是应用程序自己的事情
malloc 和 free
多线程安全下的性能
在大区间 [L,R) 中维护互不相交的区间的集合 \(M={[l_0,r_0), [l_1,r_1), ... [ln0,r_n)}\)
- \(malloc(s)\):返回大小为 s 的区间
- 必要时可以向操作系统申请额外的[L,R) (观察 strace)
- 允许在内存不足时 “拒绝” 请求
- \(free(l,r)\):给定 \(l\),删除 \([l,r) \in M\)
高效的 malloc/free
Permature optimazation is the root of all evil. -- D.E.Knuth
- 脱离 workload 做优化就是耍流氓(真实场景,benchmark)
paper:
Workload 分析
在实际系统中,我们通常不考虑 adversarial 的 worst case
- 指导思想:O(n) 大小的对象分配后至少有 Ω(n) 的读写操作,否则就是 performance bug (不应该分配那么多)
- 越小的对象创建/分配越频繁:优化的方向
- 字符串、临时对象等;生存周期可长可短
- 较为频繁地分配中等大小的对象
- 较大的数组、复杂的对象;更长的生存周期
- 低频率的大对象
- 巨大的容器、分配器;很长的生存周期
- 并行、并行、再并行
- 所有分配都会在所有处理器上发生
- 使用链表/区间树 (first fit) 可不是个好想法:无法并行
Fast and Slow
设置两套系统:
- Fast path
- 性能极好、并行度极高、覆盖大部分情况
- 但有小概率会失败 (fall back to slow path)
- Slow path
- 不在乎那么快
- 但把困难的事情做好:计算机系统里有很多这样的例子 (比如 cache)
人类也是这样的系统
- Daniel Kahneman. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011.
malloc: Fast Path 设计
使所有 CPU 都能并行地申请内存
- 线程都事先瓜分一些 “领地” (thread-local allocation buffer)
- 默认从自己的领地里分配
- 除了在另一个 CPU 释放,
acquire lock几乎总是成功 - 如果自己的领地不足,就从全局的池子里借一点
不要在乎一点小的浪费
- 这就是为什么要对齐到 \(2^k\) 字节
小内存:Segregated List
分配: Segregated List (Slab)
- 每个 slab 里的每个对象都一样大
- 每个线程拥有每个对象大小的 slab
- fast path → 立即在线程本地分配完成
- slow path → pgalloc()
- 两种实现
- 全局大链表 v.s. List sharding (per-page 小链表)
回收
- 直接归还到 slab 中
- 注意这可能是另一个线程持有的 slab,需要 per-slab 锁 (小心数据竞争)
大内存:一把大锁保平安
Buddy system (1963)
- 如果你想分配 1, 2, 3, 4, ...n个连续的页面?
- 例如:64 KB/页面
- 那就 first fit 或者 best fit 吧……
你只需要一个数据结构解决问题
- 区间树;线段树……
现实世界中的 malloc/free
以上就是所有现代 malloc/free 实现的基础