操作系统进程的实现
本讲内容:
- 进程的实现
- 处理器调度
进程的实现
Thread-OS/Lab2
实现了在多个线程之间切换
Context *on_interrupt(Event ev, Context *ctx) {
if (!current) {
current = &tasks[0]; // First trap
} else {
current->context = ctx;
current = current->next;
}
return current->context;
}
内核线程 v.s. 进程,还差了什么?-- 一个VR 眼镜
进程的地址空间
pmap: 进程拥有 \([0,2^{64}]\) 的地址空间
- 虚拟的地址空间,物理内存也就是从 0 开始的几个 GB
地址翻译:
- 计算机系统中的一个数据结构𝑓(𝑥)f(x)
- 把虚拟内存地址翻译成物理内存地址
-
由寄存器 (例如 x86 的 CR3) 和内存共同描述
-
地址翻译 (VR 眼镜) 是强制的
- 用户程序 mov CR3 将导致 #GP 异常
- 越权访问/非法访问将导致 #PF 异常 (Page Fault)
AbstractMachine 对地址空间的抽象
AddrSpace 就是一个数据结构 f
- 支持对数据结构的动态调整 (map)
- 可以创建一个 “戴 VR 眼镜” 的 kcontext (线程) --> 就是进程!
bool vme_init (void *(*alloc)(int), void (*free)(void *));
void protect (AddrSpace *as);
void unprotect(AddrSpace *as);
void map (AddrSpace *as, void *va, void *pa, int prot);
Context *ucontext (AddrSpace *as, Area kstk, void *entry);
虚假的地址空间
延迟映射:类似VR 眼镜,眼睛还没看到的地方可以先不显示
- 操作系统只要用一个数据结构记录哪段内存是什么
- 进程可以使用超过物理内存的虚拟内存 (swap)
- Page Fault 的时候再分配
- 文件 → 映射文件内容后返回
- 匿名数据 → 分配物理页面后返回
- 非法访问 → SIGSEGV
- 用什么样的数据结构实现?--> 红黑树
代码共享:比 VR 眼镜高级的功能:多个位置共享同一块屏幕
- 厉害的操作系统,同一份代码仅有一个副本
- 如何间接证实这一点?
- 通过
.fill汇编填充代码,生成128M的 a.out,运行1000个 a.out,内存没有卡死;
- 通过
- 如何直接确认这一点?
- AskGPT: How to print the corresponding physical address of a given virtual address in Linux user space in C?
写时复制:除了万不得已,能不复制就不复制
- 即便使用了很多内存,fork() 依然可以在瞬间完成
- fork-execve 非常常见,刚复制完 1GB 内存,就销毁了
处理器调度原理
问题
操作系统具有在中断后选择任何进程执行的权利
- 那应该选哪个比较好……呢?1950-1960s 操作系统研究的重要话题
Context *on_interrupt(Event ev, Context *ctx) {
if (!current) {
current = &tasks[0]; // First trap
} else {
current->context = ctx;
current = current->next; // Round-robin 轮转调度
}
return current->context;
}
设计空间
- 建模 (理解和总结 “过去发生了什么”)
- 预测 (试图预知未来可能发生什么)
- 决策 (在预测下作出对系统最有利的选择)
允许用户定制处理器调度
UNIX niceness
- -20 .. 19 的整数,越 nice 越让别人得到 CPU
- -20: 极坏; most favorable to the process
- 19: 极好; least favorable to the process
- 基于优先级的调度策略
- RTOS: 坏人躺下好人才能上
Linux: 10 nice的差别 ≈ CPU 资源获得率相差 10 倍
- 不妨试一试: nice/renice,查看 CPU 的利用率
Round-Robin 的缺陷
系统里有两个进程
- 交互式的 Vim,单线程
- 纯粹计算的 mandelbrot.c, 32 个线程
Round-Robin
- Vim 花 0.1ms 处理完输入就又等输入了
- 主动让出 CPU
- Mandelbrot 使 Vim 在有输入可以处理的时候被延迟
- 必须等当前的 Mandelbrot 转完一圈
- 数百 ms 的延迟就会使人感到明显卡顿
策略:动态优先级 (MLFQ)
不会设置优先级?让系统自动设定!
- 设置若干个 Round-Robin 队列
- 每个队列对应一个优先级
- 动态优先级调整策略:优先调度高优先级队列
- 用完时间片 → 坏人
- 让出 CPU I/O → 好人
策略:Complete Fair Scheduling (CFS)
试图去模拟一个 “Ideal Multi-Tasking CPU”:
- “Ideal multi-tasking CPU” is a (non-existent :-)) CPU that has 100% physical power and which can run each task at precise equal speed, in parallel, each at . For example: if there are 2 tasks running, then it runs each at 50% physical power — i.e., actually in parallel.
“让系统里的所有进程尽可能公平地共享处理器”
- 为每个进程记录精确的运行时间
- 中断/异常发生后,切换到运行时间最少的进程执行
- 下次中断/异常后,当前进程的可能就不是最小的了
CFS: 实现优先级
操作系统具有对物理时钟的 “绝对控制”
- 每人执行 1ms,但好人的钟快一些,坏人的钟慢一些
vruntime (virtual runtime)vrt[i] / vrt[j]的增加比例 =wt[j] / wt[i]
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
🌶️真实的处理器调度
优先级带来的问题
低优先级的代码获取到锁,但是被赶下处理器;高优先级无法获取锁,无法执行;
中优先级的代码一直运行;
void jyy() { // 最低优先级
mutex_lock(&wc_lock);
// 先到先得
}
void xi_zhu_ren() { // 中优先级
while (1) ;
}
void xiao_zhang() { // 高优先级
sleep(1);
mutex_lock(&wc_lock);
...
}
解决优先级反转问题
Linux: 解决不了,CFS 凑合用吧。
实时系统:
- 优先级继承 (Priority Inheritance)/优先级提升 (Priority Ceiling)
- 持有 mutex 的线程/进程会继承 block 在该 mutex 上进程的最高优先级
- 但也不是万能的 (例如条件变量唤醒)
- 在系统中动态维护资源依赖关系
- 优先级继承是它的特例
- 似乎更困难了……
- 避免高/低优先级的任务争抢资源
- 对潜在的优先级反转进行预警 (lockdep)
- TX-based: 冲突的 TX 发生时,总是低优先级的 abort
多处理器调度:被低估的复杂性
“And you have to realize that there are not very many things that have aged as well as the scheduler. Which is just another proof that scheduling is easy.” ——Linus Torvalds, 2001
- As a central part of resource management, the OS thread scheduler must maintain the following, simple, invariant:make sure that ready threads are scheduled on available cores ... this invariant is often broken in Linux. Cores may stay idle for seconds while ready threads are waiting in runqueues.
- The Linux scheduler: A decade of wasted cores. (EuroSys'16):作者在狂黑 Linus 😂
多处理器调度的困难所在
- 既不能简单地 “分配线程到处理器”
-
线程退出,瞬间处理器开始围观
-
也不能简单地 “谁空丢给谁”
-
在处理器之间迁移会导致 cache/TLB 全都白给
-
多处理器调度的两难境地
-
迁移?可能过一会儿还得移回来
-
不迁移?造成处理器的浪费
实际情况 (1): 多用户、多任务
不同的用户可以创建多个线程,占用很多的资源。
- A 要跑一个任务,调用一个库,只能单线程跑
- B 跑并行的任务,创建 10,000 个线程跑(获得几乎100%的CPU)
非特权用户无法提高自己的进程的优先级:
- an unprivileged user can only increase the "nice value" (i.e., choose a lower priority) and such changes are irreversible
Linux Namespaces Control Groups (cgroups) 作为解决方案:Docker 的基础
- 轻量级虚拟化,创造 “操作系统中的操作系统”
- Mount, pid, network, IPC, user, cgroup namespace, time
-
cgroup 允许以进程组为单位管理资源
-
askGPT:如何使用 crgoup 限制用户的CPU/Memory 使用?
实际情况 (2): Big.LITTLE/能耗
骁龙 888:大小核
- 1X Prime Cortex-X1 (2.84GHz)
- 3X Performance Cortex-A78 (2.4GHz)
- 4X Efficiency Cortex-A55 (1.8GHz)
“Dark silicon” (暗硅)时代的困境
-
功率无法支撑所有电路同时工作,总得有一部分是停下的
-
Linux Kernel EAS (Energy Aware Scheduler)
软件可以配置 CPU 的工作模式
- 开/关/工作频率 (频率越低,能效越好)
- 如何在给定功率下平衡延迟 v.s. 吞吐量?
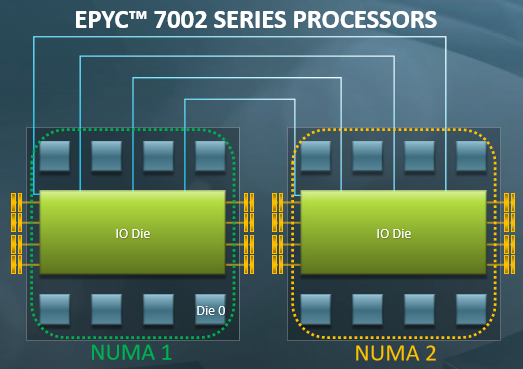
实际情况 (3): Non-Uniform Memory Access
通过 lscpu 可以查看 NUMA 和 CPU 的对应关系
共享内存只是假象
- L1 Cache 花了巨大的代价才让你感到内存是共享的
- Producer/Consumer 位于同一个/不同 module 性能差距可能很大
基本的假设可能不再成立:cache 导致多线程的性能下降
- 例子: more CPU time, more progress
- 分配了 1/2 的处理器资源,反而速度更快
实际情况 (4): CPU Hot-plug
复杂的系统无人可以掌控
- The battle of the schedulers: FreeBSD ULE vs. Linux CFS. (ATC'18)
- 结论:在现实面前,没有绝对的赢家和输家
- 如果你追求极致的性能,就不能全指望一个调度算法
课后习题/编程作业
1. 阅读材料
教科书 Operating Systems: Three Easy Pieces
- 第 15 章 - Address Translation
- 第 16 章 - Segmentation
- 第 17 章 - Free Space Management
- 第 18 章 - Introduction to Paging
- 第 19 章 - Translation Lookaside Buffers
- 第 20 章 - Advanced Page Tables
- 第 21 章 - Swapping: Mechanisms
- 第 22 章 - Swapping: Policies
- 第 23 章 - Complete VM Systems