散列(Hash)算法
Hash函数
哈希(Hash)算法,即散列函数。一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程,没有解密过程。
常见的Hash函数(int hash(bytes[])):源码见
-
Java Hash:c = c * 31 + b[i];
-
Crc32 Hash:循环冗余校验码的结果做Hash;
- Ketama Hash:基于 MD5 摘要,取最后4字节;
- MurMur Hash:非加密HASH算法,性能很高
-
基本思想就是把key分成n组,每组4个字符,把这4个字符看成是一个uint_32,进行n次运算,得到一个h,然会在对h进行处理,得到一个相对离散的hash code;
-
fnv1/fnv1A Hash:高效性和低冲突率,适用于哈希一些相近的字符串,如IP地址、URL和文件名等
分布式Hash
分布式Hash一般用作分布式的缓存服务,比如Redis和Memcache。
判定哈希算法好坏的四个定义:
-
平衡性(Balance):哈希的结果能够尽可能分布到所有的缓冲中去,大部分Hash算法都满足;
-
单调性(Monotonicity):当缓冲增加时,保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区;
- 分散性(Spread):相同的内容被不同的终端映射到不同的缓冲区中,分散性的定义就是上述情况发生的严重程度;应该避免分散性;
- 负载(Load):特定的缓冲区而言,也可能被不同的用户映射为不同的内容,应该尽量降低缓冲的负荷;
简单哈希算法
假设有三台机,数据落在哪台机的算法为
例如key A的哈希值为4,4%3=1,则落在第二台机。Key ABC哈希值为11,11%3=2,则落在第三台机上。
利用这样的算法,假设现在数据量太大了,需要增加一台机器。A原本落在第二台上,现在根据算法4%4=0,落到了第一台机器上了,但是第一台机器上根本没有A的值。这样的算法会导致增加机器或减少机器的时候,引起大量的缓存穿透,造成雪崩。
一致性Hash算法
算法流程:
- 环形Hash空间:将value映射成 0 ~ 2^32 - 1的环形空间,将对象object和cache都映射到同一个Hash空间中,使用同样的Hash算法;
- object -> cache:从object的hash值顺时针出发,匹配到最近的cache的hash值。
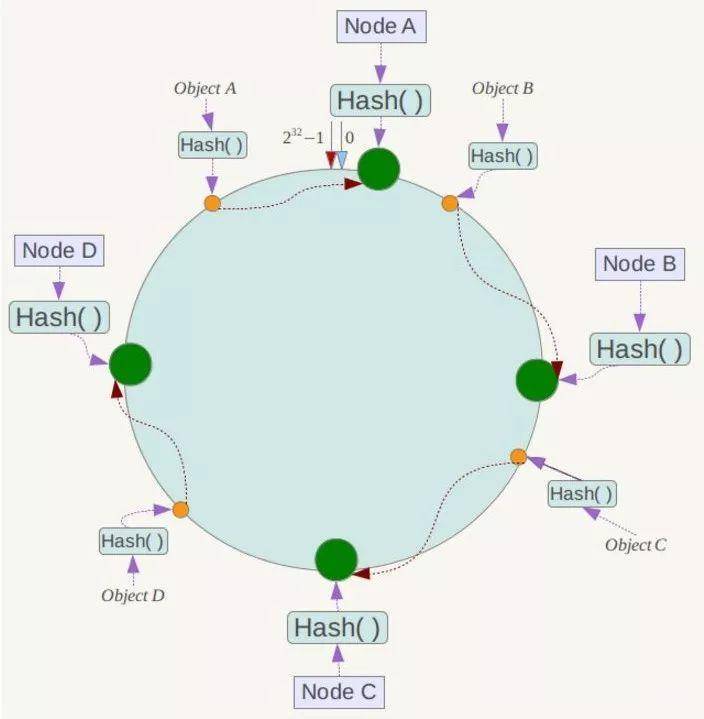
解决单调性:
- 移除/添加节点Cache B时,受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache A之间的对象,即是本来映射到 cache B 上的那些对象;
满足负载均衡,解决平衡性:
- 解决cache数过少导致分布不平衡的问题。“虚拟节点”(virtual node)是实际节点在 hash 空间的复制品(replica),一个实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
缺点:
-
无法控制节点存储数据的分配,需要实际评估每个节点分配的hash空间范围是否均匀;
-
对 Hash 算法有要求,对近似的 key 其Hash的结果应该均匀分布在不同空间:
- 比如对 局域网的IP 进行 Hash,则 Java String
hashcode出来的值会分布在一个空间;
Hash槽
Redis Cluster采用的方案,Redis Cluster的hash算法是crc16算法,一种校验算法。
Redis Cluster包含了16384个哈希槽,每个Key通过计算后都会落在具体一个槽位,哪个节点负责哪些槽位,可以自行指定或者自动生成。
数据结构
- 每个节点通过16384/8个byte保存其负责的槽位(对应bit为1);
- 节点同时维护16384长度的数组表示槽位到集群节点的映射。