多处理器编程:从入门到放弃
本讲内容:多处理器编程:从入门到放弃:
- 入门:多线程编程库
- 放弃:原子性、顺序性、可见性
多处理器编程入门
多线程共享内存并发
线程:共享内存的执行流
- 执行流拥有独立的堆栈/寄存器
简化的线程 API (thread.h)
spawn(fn)- 创建一个入口函数是 fn 的线程,并立即开始执行
void fn(int tid) { ... }- 参数
tid从 1 开始编号
- 行为:
sys_spawn(fn, tid) join()- 等待所有运行线程的返回 (也可以不调用)
- 行为:
while (done != T) sys_sched()
入门和问题
多处理器编程:一个 API 搞定
thread.h在随堂代码中,提供create函数创建thread;- 操作系统会自动把线程放置在不同的处理器上
- 通过
top命令查看,CPU 使用率超过了 100%
#include "thread.h"
void Ta() { while (1) { printf("a"); } }
void Tb() { while (1) { printf("b"); } }
int main() {
create(Ta);
create(Tb);
}
问题1:Ta 和 Tb 真的共享内存么?
- 证明:定义全局变量,两个线程都可以对其操作;
问题2:如何证明线程具有独立的堆栈(以及确定的堆栈的大小范围?)
- 函数里声明的变量(栈上的变量),其它线程无法进行修改;
- 栈的范围:无穷递归,通过局部变量的地址来估算分配给线程的栈空间;
更多的问题:
- 创建线程使用的是哪个系统调用:
clone - 能不能用 gdb 调试?能,RTFM
放弃 (1):原子性
状态机的隐含假设
“世界上只有一个状态机”
- 没有其他任何人能 “干涉” 程序的状态
- 推论:对变量的 load 一定返回本线程最后一次 store 的值
- 这也是编译优化的基本假设
但共享内存推翻了这个假设
- 其他线程随时可以修改
x - 导致两次可能读到不同的
x
并发 Bug 示例
相关代码在随堂代码中
Talipay_withdraw:两个线程并发支付 ¥100 会发生什么(无符号 int 没有负数,用不完的钱);
Tsum:多线程求和;
- 即使用汇编指令(sum++)也不行,无法保证单条指令在多处理器上执行的原子性
放弃 (1):指令/代码执行原子性假设
“处理器一次执行一条指令” 的基本假设在今天的计算机系统上不再成立 (我们的模型作出了简化的假设)。
- 多处理器导致单条指令执行的不原子性(单处理器的中断只发生在指令边缘,可以保证单挑指令原子性);
单处理器多线程
- 线程在运行时可能被中断,切换到另一个线程执行
多处理器多线程
- 线程根本就是并行执行的
(历史) 1960s,大家争先在共享内存上实现原子性 (互斥)
- 但几乎所有的实现都是错的,直到 Dekker's Algorithm,还只能保证两个线程的互斥
放弃原子性假设的后果
printf还能在多线程程序里调用吗?- 通过
man printf查看,其是线程安全的,RTFM;
放弃 (2):执行顺序
求和示例的不同编译优化
下面的求和代码,如果添加编译优化?
-O1: 结果是:100000000-O2: 结果是:200000000
#define N 100000000
long sum = 0;
void Tsum() { for (int i = 0; i < N; i++) sum++; }
int main() {
create(Tsum);
create(Tsum);
join();
printf("sum = %ld\n", sum);
}
放弃 (2):程序的顺序执行假设
编译器对内存访问 “eventually consistent” 的处理导致共享内存作为线程同步工具的失效。
通过查看O1和O2优化后的 Tsum 的汇编指令:你的编译器也许是不同的结果
- O1:先将 sum 的值放到寄存器,然后寄存器循环加,最后赋值到 sum;
R[eax] = sum; R[eax] += N; sum = R[eax]- O2:直接变成一条指令(如果线程多,是不是仍会结果错误?)
sum += N;
另一个例子
保证执行顺序
回忆 “编译正确性”
-
C 状态和汇编状态机的 “可观测行为等价”
-
方法 1:插入 “不可优化” 代码
-
“Clobbers memory”:表明内联汇编代码改变了内存中的值,强迫编译器在执行该汇编代码前存储所有缓存的值,在执行完汇编代码之后重新加载该值,目的是防止编译乱序
-
c asm volatile ("" ::: "memory"); -
方法 2:标记变量 load/store 为不可优化
-
使用
volatile变量
放弃 (3):处理器间的可见性
示例
int x = 0, y = 0;
void T1() {
x = 1; int t = y; // Store(x); Load(y)
__sync_synchronize();
printf("%d", t);
}
void T2() {
y = 1; int t = x; // Store(y); Load(x)
__sync_synchronize();
printf("%d", t);
}
遍历模型(不同的执行顺序)告诉我们:01, 10, 11
- 但执行程序可以输出
00,机器永远是对的 - Model checker 的结果和实际的结果不同 → (Model checker)假设错了
现代处理器也是 (动态) 编译器
错误 (简化) 的假设(Model checker)
- 一个 CPU 执行一条指令到达下一状态
多处理器间即时可见性的丧失:CPU的指令重排序优化,内存同步障解决问题
- 单个处理器把汇编代码“编译”成更小的\(\mu ops\),每个\(\mu ops\) 都有 Fetch, Issue, Execute, Commit 四个阶段
- “多发射”:每一周期向池子补充尽可能多的 \(\mu op\)
- “乱序执行”、“按序提交”:每一周期 (在不违反编译正确性的前提下) 执行尽可能多的 \(\mu op\)
| 电路将连续的指令 “编译” 成更小的 μops - RF[9] = load(RF[7] + 400) - store(RF[12], RF[13]) - RF[3] = RF[4] + RF[5] |
 |
|---|---|
多处理器间内存访问的即时可见性
满足单处理器 eventual memory consistency 的执行,在多处理器系统上可能无法序列化!
当 \(x \ne y\) 时,对 \(x,y\) 的内存读写可以交换顺序
- 它们甚至可以在同一个周期里完成 (只要 load/store unit 支持)
- 如果写\(x\)发生 cache miss,可以让读 \(y\) 先执行
- 满足 “尽可能执行μop” 的原则,最大化处理器性能
- 在多处理器上的表现
- 两个处理器分别看到 \(y=0\) 和 \(x=0\)
宽松内存模型 (Relaxed/Weak Memory Model)
宽松内存模型的目的是使单处理器的执行更高效。
x86 已经是市面上能买到的 “最强” 的内存模型了
-
这也是 Intel 自己给自己加的包袱
-
每个处理器,先写到单独的队列,然后再写到共享内存;
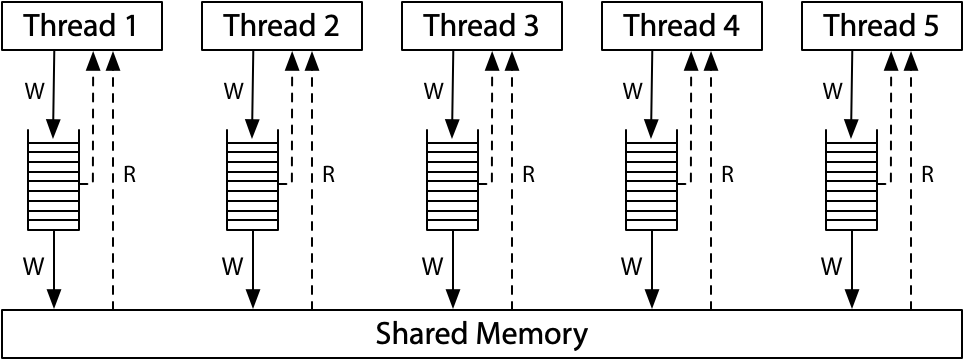
-
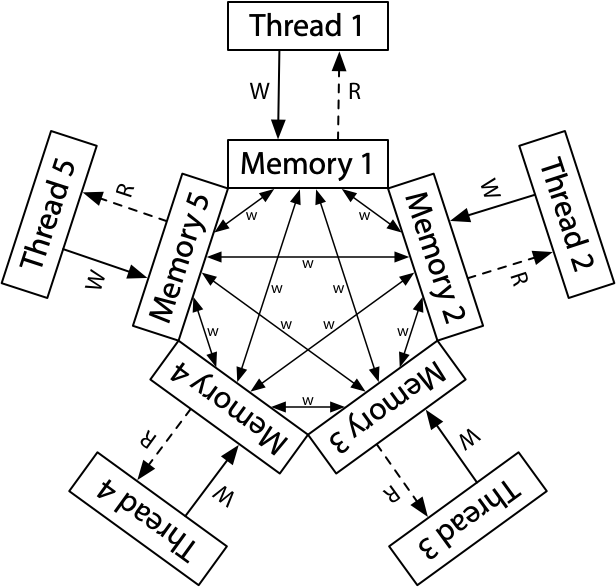
看看 ARM/RISC-V 吧,根本就是个分布式系统
-
最终一致性
课后阅读
教科书 Operating Systems: Three Easy Pieces:
编程作业
- 在你的 Linux 中运行课堂上的代码示例;
- thread.h 可以学习的编程技巧,例如 constructor 和 destructor 等;