持久数据的可靠性
本讲内容:
- 持久数据的可靠性
- 构建可靠的磁盘
- fsck 和 journaling
持久数据的可靠性
任何物理存储介质都有失效的可能
-
临时失效:Kernel panic;断电
-
永久失效
- 极小概率事件:战争爆发/三体人进攻地球/世界毁灭
- 小概率事件:硬盘损坏 (大量重复 = 必然发生)
Failure Model (1): Fail-stop
磁盘可能在某个时刻忽然彻底无法访问
- 机械故障、芯片故障……
- 磁盘好像就 “忽然消失” 了 (数据完全丢失)
- 假设磁盘能报告这个问题 (如何报告?)
磁盘发生 fail-stop 会对你带来什么影响?
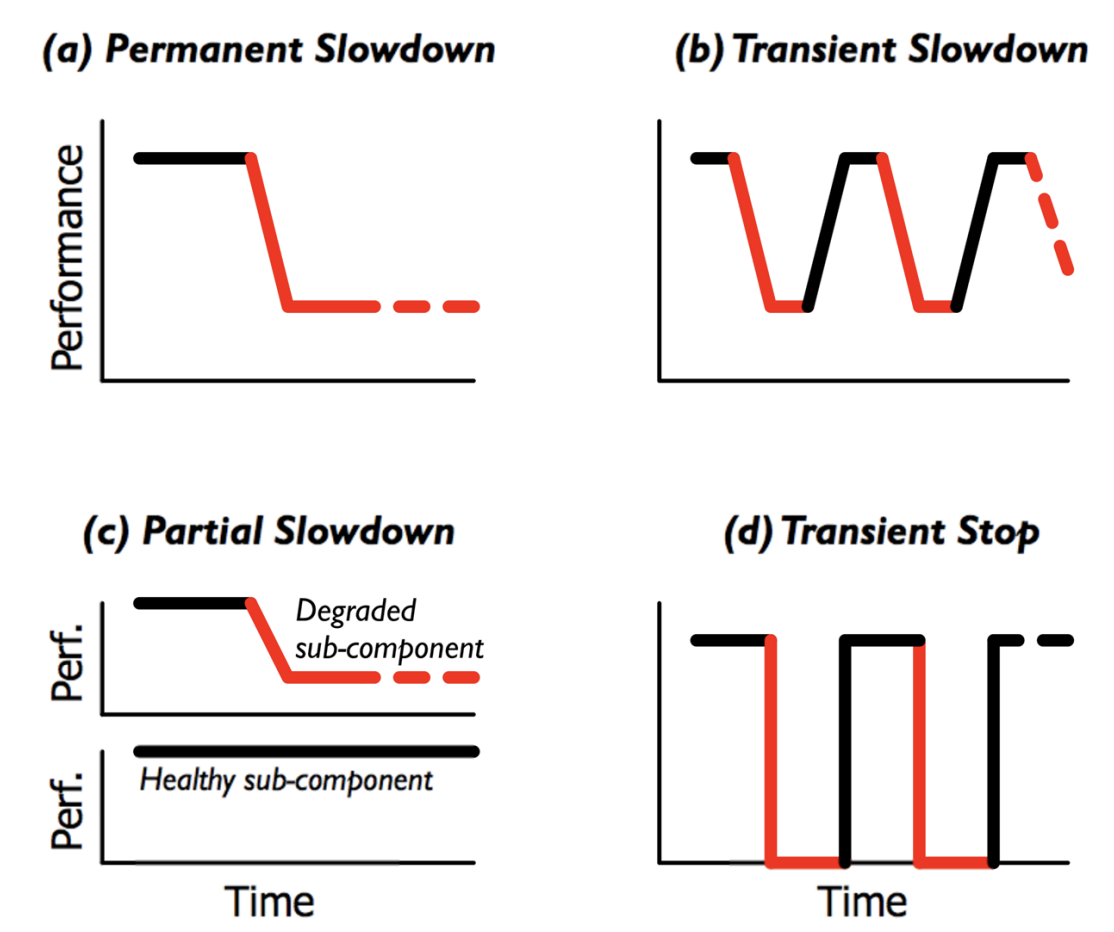
Failure Model (2): System Crash
真实的磁盘
bwrite会被磁盘缓存,并且以不可控的顺序被persist- 在任何时候,系统都可能 crash
bsync会等待所有bwrite落盘
System crash 会对你带来什么影响?
更多的 Failure Mode
Data corruption
- 磁盘看起来正常,但一部分数据坏了
- An analysis of data corruption in the storage stack (FAST'08)
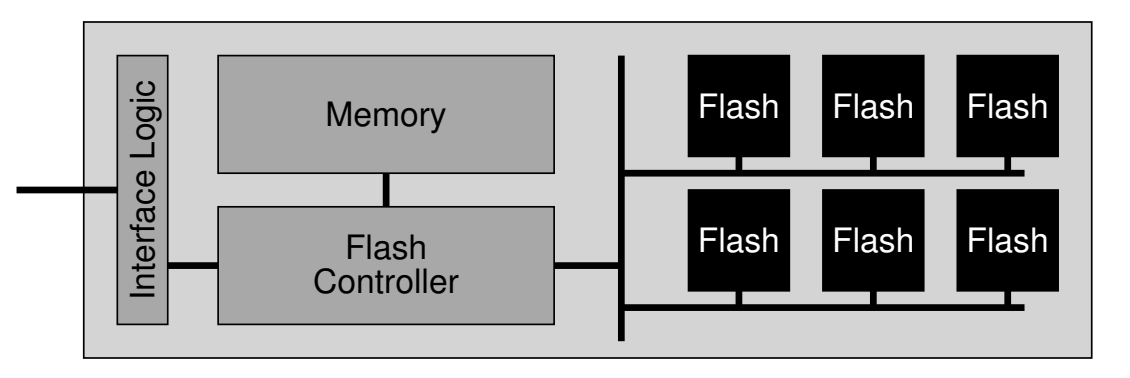
Fail-slow:硬件或系统仍在运行,但其性能显著下降的状态
- Firmware bug; device error; wear-out; configuration; environment; ...
- Fail-slow at scale: Evidence of hardware performance faults in large production systems (FAST'18)
Redundant Array of Inexpensive Disks (RAID)
RAID: 存储设备的虚拟化
把多个 (不可靠的) 磁盘虚拟成一块非常可靠且性能极高的虚拟磁盘
-
A case for redundant arrays of inexpensive disks (RAID) (SIGMOD'88)
-
一个 “反向” 的虚拟化
- 类比:进程/虚存/文件把 “一个设备” 虚拟成多份
RAID: Design Space
RAID (虚拟化) = 虚拟磁盘块到物理磁盘块的 “映射”。
- 虚拟磁盘块可以存储在任何虚拟磁盘上
- 虚拟磁盘可以并行
- 存储 >1 份即可实现容错
RAID-0:更大的容量、更快的速度,没有容错
- 读速度 x 2;写速度 x 2
RAID-1:镜像 (容错)
- 保持两块盘完全一样
- 读速度 x 2;写速度保持一致
RAID-1容错的代价
浪费了一块盘的容量……
- 如果我们有 100 块盘,但假设不会有两块盘同时 fail-stop?
能不能只用 1-bit 的冗余,恢复出一个丢失的 bit?
- 𝑥=𝑎⊕𝑏⊕𝑐⊕𝑑
- 𝑎=𝑥⊕𝑏⊕𝑐⊕𝑑
- 𝑏=𝑎⊕𝑥⊕𝑐⊕𝑑
- 𝑐=𝑎⊕𝑏⊕𝑥⊕𝑑
- 𝑑=𝑎⊕𝑏⊕𝑐⊕𝑥
- 100 块盘里,99 块盘都是数据!
- Caveat: random write 性能:校验盘(parity block)需要先读出来,再写进入(瓶颈)
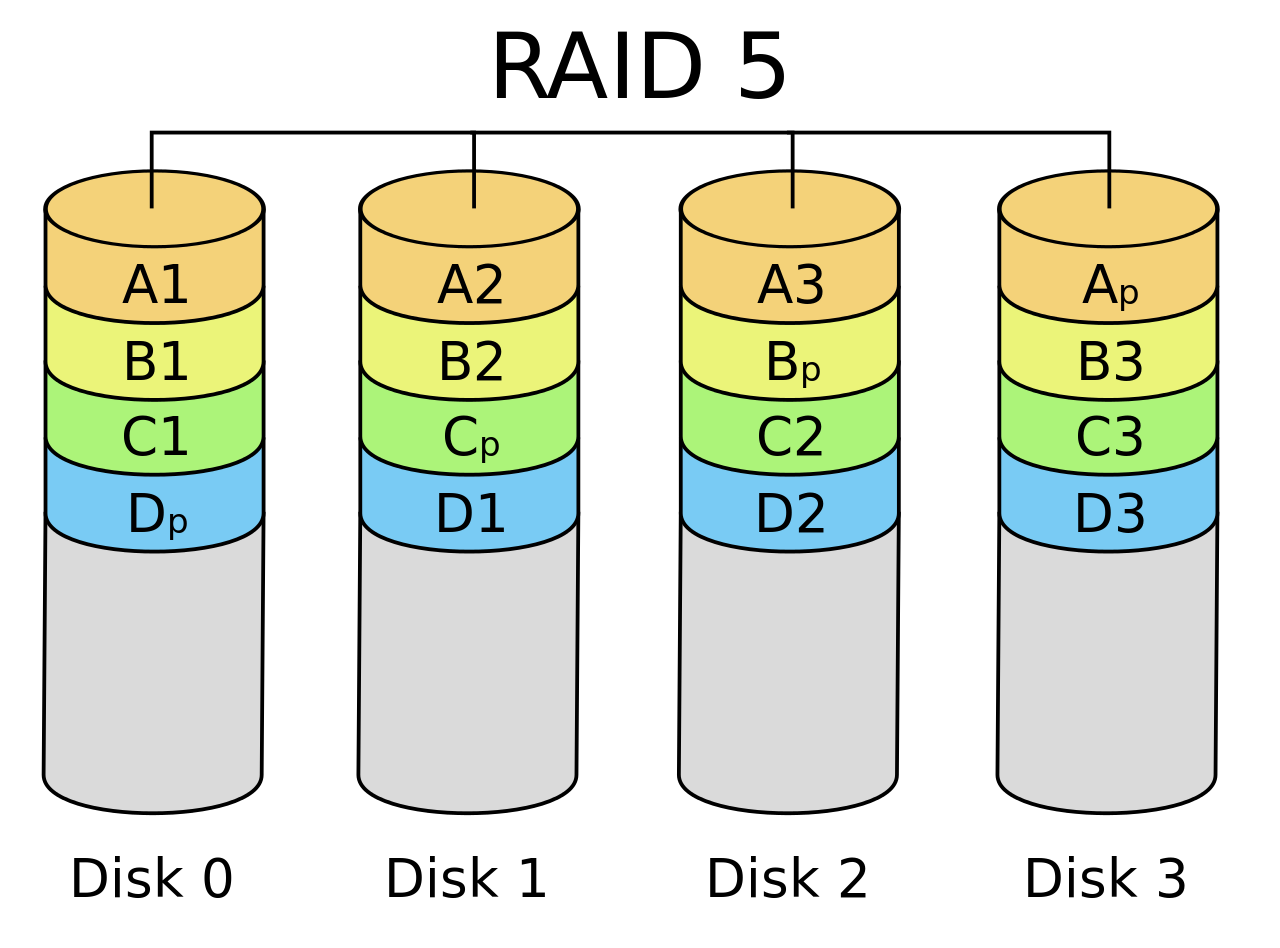
RAID-5: Rotating Parity
“交错排列” parity block!
RAID: 讨论
更快、更可靠、近乎免费的大容量磁盘
- 革了 “高可靠性磁盘” 的命
- 成为今天服务器的标准配置
- 类似的里程碑:“大数据” 时代
- The Google file system (SOSP'03) 和 MapReduce: Simplified data processing on large clusters (OSDI'04)
RAID 的可靠性
- RAID 系统发生断电?
- 例子:RAID-1 镜像盘出现不一致的数据
- 检测到磁盘坏?
- 自动重组
崩溃一致性与崩溃恢复
崩溃一致性 (Crash Consistency)
Crash Consistency: Move the file system from one consistent state (e.g., before the file got appended to) to another atomically (e.g., after the inode, bitmap, and new data block have been written to disk).
磁盘不提供多块读写 “all or nothing” 的支持
- 甚至为了性能,没有顺序保证
- bwrite 可能被乱序
- 所以磁盘还提供了 bflush 等待已写入的数据落盘
File System Checking (FSCK)
根据磁盘上已有的信息,恢复出 “最可能” 的数据结构
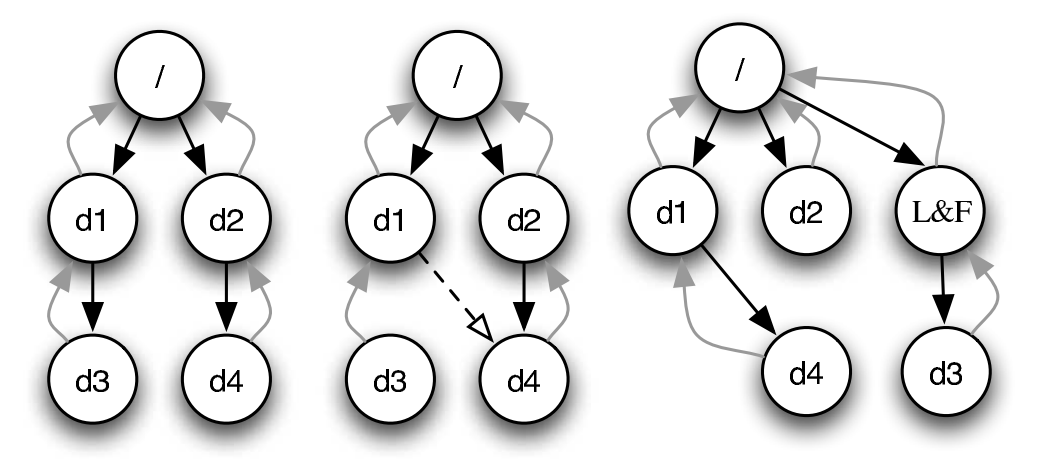
- SQCK: A declarative file system checker (OSDI'08)
- Towards robust file system checkers (FAST'18)
- “widely used file systems (EXT4, XFS, BtrFS, and F2FS) may leave the file system in an uncorrectable state if the repair procedure is interrupted unexpectedly” 😂
重新思考数据结构的存储
两个 “视角”
- 存储实际数据结构
- 文件系统的 “直观” 表示
- crash unsafe
- Append-only 记录所有历史操作
- “重做” 所有操作得到数据结构的当前状态
- 容易实现崩溃一致性
二者的融合
- 数据结构操作发生时,用 (2) append-only 记录日志
- 日志落盘后,用 (1) 更新数据结构
- 崩溃后,重放日志并清除 (称为 redo log;相应也可以 undo log)
实现 Atomic Append
用 bread, bwrite 和 bflush 实现 append()
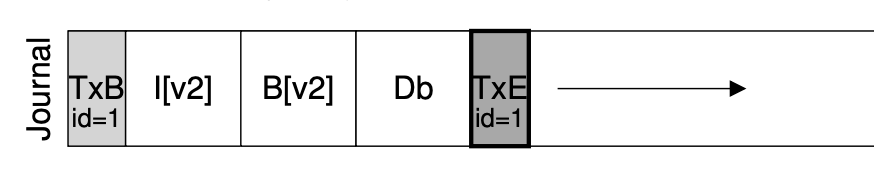
- 定位到 journal 的末尾 (bread)
- bwrite TXBegin 和所有数据结构操作
- bflush 等待数据落盘(防止 TxEnd 乱序先写入)
- bwrite TXEnd
- bflush 等待数据落盘(两个 flush 具备 happens-before)
- 将数据结构操作写入实际数据结构区域
- 等待数据落盘后,删除 (标记) 日志
Journaling: 优化
现在磁盘需要写入双份的数据
- 批处理 (xv6; jbd)
- 多次系统调用的 Tx 合并成一个,减少 log 的大小
- jbd: 定期 write back
- Checksum (ext4)
- 不再标记 TxBegin/TxEnd
- 直接标记 Tx 的长度和 checksum
- Metadata journaling (ext4 default)
- 数据占磁盘写入的绝大部分
- 只对 inode 和 bitmap 做 journaling 可以提高性能
- 保证文件系统的目录结构是一致的;但数据可能丢失
Metadata Journaling
从应用视角来看,文件系统的行为可能很怪异
- 各类系统软件 (git, sqlite, gdbm, ...) 不幸中招
- All file systems are not created equal: On the complexity of crafting crash-consistent applications (OSDI'14)
- 更多的应用程序可能发生 data loss
- 我们的工作: GNU coreutils, gmake, gzip, ... 也有问题
- Crash consistency validation made easy (FSE'16)
更为一劳永逸的方案:TxOS
- xbegin/xend/xabort 系统调用实现跨 syscall 的 “all-or-nothing”
- 应用场景:数据更新、软件更新、check-use……
- Operating systems transactions (SOSP'09)
课后习题/编程作业
1. 阅读材料
教科书 Operating Systems: Three Easy Pieces
- 第 38 章 - Redundant Disk Arrays (RAID)
- 第 42 章 - FSCK and Journaling
- 第 43 章 - Log-structured File System (LFS)