并发控制:互斥
本讲内容:现代多处理器系统上的互斥实现:
- 互斥问题的定义和假设
- 自旋锁
- 互斥锁和 Futex
互斥问题:定义与假设
互斥问题:定义
互斥 (mutual exclusion),“互相排斥”
- 实现
lock_t数据结构和lock/unlockAPI:
一把 “排他性” 的锁——对于锁对象 lk
- 如果某个线程持有锁,则其他线程的
lock不能返回 (Safety) - 在多个线程执行
lock时,至少有一个可以返回 (Liveness) - 能正确处理处理器乱序、宽松内存模型和编译优化
实现互斥的基本假设
允许使用使我们可以不管一切麻烦事的原子指令
看起来是一个普通的函数,但假设:
- 原子性:包含一个原子指令
- 指令的执行不能被打断
- 执行顺序:包含一个 compiler barrier
- 无论何种优化都不可越过此函数
- 可见性:包含一个 memory fence
- 保证处理器在 stop-the-world 前所有对内存的 store 都 “生效”
- 即对 resume-the-world 之后的 load 可见
Atomic Exchange 实现
int xchg(int volatile *ptr, int newval) {
int result;
asm volatile(
// 指令自带 memory barrier
"lock xchgl %0, %1"
: "+m"(*ptr), "=a"(result)
: "1"(newval)
// Compiler barrier
: "memory"
);
return result;
}
自旋锁(Spin Lock)
科学家:考虑更多更根本的问题
- 我们可以设计出怎样的原子指令?
- 它们的表达能力如何?
- 计算机硬件可以提供比 “一次 load/store” 更强的原子性吗?
- 如果硬件很困难,软件/编译器可以么?
自旋锁:用 xchg 实现互斥
Lock 保护临界区,临界区的变量不需要任何修饰。不同的 Lock 是并发的,是如何实现的?
- 每次都是要将数据写内存/读内存,不同的锁之间也会有影响?
- 看 memory fence 的定义
- lock 和 unlock 间的代码是可以进行优化的;
在 xchg 的假设下简化实现
- 包含一个原子指令
- 包含一个 compiler barrier
- 包含一个 memory fence
// 用 model checker 中检查
int locked = 0;
void lock() {
while (xchg(&locked, 1));
}
void unlock() {
// X86 架构下,可以用直接locked == 0,只需要防止编译优化即可。
xchg(&locked, 0);
}
你们 (不) 想要的无锁算法
更强大的原子指令
Compare and exchange (“test and set”)
- (lock)
cmpxchg SRC, DEST
# https://www.felixcloutier.com/x86/cmpxchg
TEMP = DEST
if accumulator == TEMP:
ZF = 1
DEST = SRC
else:
ZF = 0
accumulator = TEMP
在自旋锁中代替 xchg
在自旋锁的实现中,xchg 完全可以用 cmpxchg 代替
- 在自旋失败的时候减少了一次 store,现代处理器也可以优化 xchg;
多出的 Compare: 用处
同时检查上一次获得的值是否仍然有效 + 修改生效
- 场景:并发的单列表,头节点的处理
// Create a new node
node = newnode();
retry:
expected = head;
node->next = expected;
seen = cmpxchg(expected, node, &head);
if (seen != expected)
goto retry;
在操作系统上实现互斥
自旋锁的缺陷
自旋 (共享变量) 会触发处理器间的缓存同步,延迟增加
- 其它锁机制也会有此类共性问题,因为不算做缺陷。
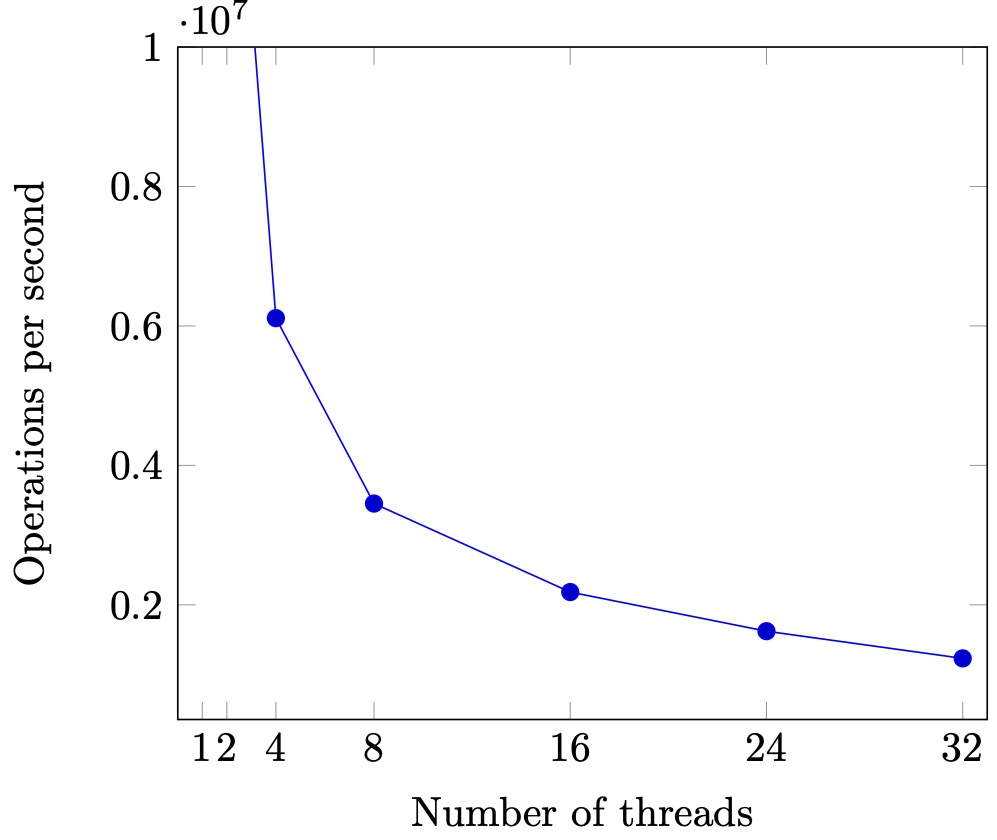
性能问题 (1)
- 除了进入临界区的线程,其他处理器上的线程都在空转
- 争抢锁的处理器越多,利用率越低
- 4 个 CPU 运行 4 个 sum-spinlock 和 1 个 OBS
- 任意时刻都只有一个 sum-atomic 在有效计算
- 均分 CPU, OBS 就分不到 100% 的 CPU 了
性能问题 (2)
- 持有自旋锁的线程可能被操作系统切换出去
- 操作系统不 “感知” 线程在做什么(但为什么不能呢?)
- 实现 100% 的资源浪费
Scalability: 性能的新维度
通过 sum++ 代码验证 spinlock 的 scalability。
- 但严谨的统计很难
- CPU 动态功耗
- 系统中的其他进程
- 超线程
- NUMA
- ……
- Benchmarking crimes
自旋锁的使用场景
- 临界区几乎不 “拥堵”
- 持有自旋锁时禁止执行流切换
使用场景:操作系统内核的并发数据结构 (短临界区)
- 操作系统可以关闭中断和抢占(只能关闭当前cpu的中断,无法关闭其它cpu)
- 保证锁的持有者在很短的时间内可以释放锁
- (如果是虚拟机呢...😂)
- PAUSE 指令会触发 VM Exit
- 但依旧很难做好
- An analysis of Linux scalability to many cores (OSDI'10)
实现线程 + 长临界区的互斥
作业那么多,与其干等 Online Judge 发布,不如把自己 (CPU) 让给其他作业 (线程) 执行?
“让” 不是 C 语言代码可以做到的 (C 代码只能执行指令)
- 但有一种特殊的指令:syscall
- 把锁的实现放到操作系统里就好啦(就是后面的 sys_futex 系统调用)
syscall(SYSCALL_lock, &lk);- 试图获得
lk,但如果失败,就切换到其他线程
- 试图获得
syscall(SYSCALL_unlock, &lk);- 释放
lk,如果有等待锁的线程就唤醒
- 释放
关于互斥的一些分析
自旋锁 (线程直接共享 locked)
- 更快的 fast path
- xchg 成功 → 立即进入临界区,开销很小
- 更慢的 slow path
- xchg 失败 → 浪费 CPU 自旋等待
互斥锁 (通过系统调用访问 locked)
- 更经济的 slow path
- 上锁失败线程不再占用 CPU
- 更慢的 fast path
- 即便上锁成功也需要进出内核 (syscall)
Futex: Fast Userspace muTexes
pthread_mutex 底层实现,采用的是 futex 实现。
- Fast path: 一条原子指令,上锁成功立即返回
- Slow path: 上锁失败,执行系统调用睡眠
- 性能优化的最常见技巧
- 看 average (frequent) case 而不是 worst case
POSIX 线程库中的互斥锁 (pthread_mutex)
-
通过
strace -f查看系统调用,发现pthread_mutex具备很多的futex系统调用; -
gdb 调试
set scheduler-locking on,info threads,thread X
附:Lock 指令的现代实现
在 L1 cache 层保持一致性 (ring/mesh bus)
- 相当于每个 cache line 有分别的锁
store(x)进入 L1 缓存即保证对其他处理器可见- 但要小心 store buffer 和乱序执行
L1 cache line 根据状态进行协调
- M (Modified), 脏值
- E (Exclusive),独占访问
- S (Shared),只读共享
- I (Invalid),不拥有 cache line
Load-Reserved/Store-Conditional (LR/SC):RISC-V, 另一种原子操作的设计
- LR: 在内存上标记 reserved (盯上你了),中断、其他处理器写入都会导致标记消除;
- SC: 如果 “盯上” 未被解除,则写入。
- 硬件实现:BOOM (Berkeley Out-of-Order Processor)
课后习题
1. 阅读材料
教科书 Operating Systems: Three Easy Pieces