模型服务KServe
https://github.com/kserve/kserve/blob/master/install/v0.9.0/kserve-runtimes.yaml
针对不同类型的ML 框架,提供不同的服务镜像。
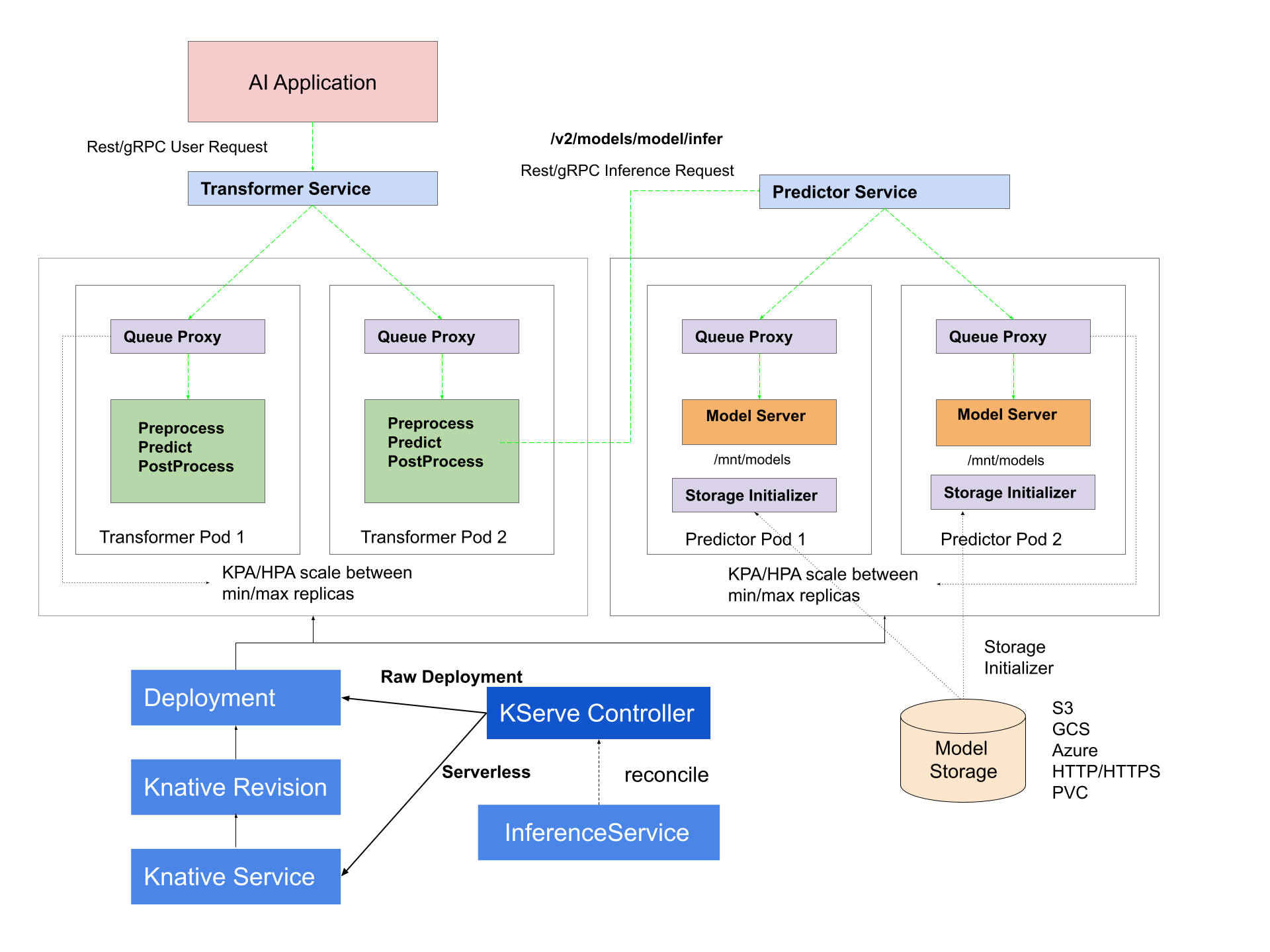
架构
控制平面
负责对
InferenceService自定义资源进行调谐。
IngressClass 通过 HEADER 控制路由?
serverless mode:creates the Knative serverless deployment for predictor, transformer, explainer to enable autoscaling
raw deployment mode:creates Kubernetes deployment, service, ingress, HPA.
组件:
- KServe Controller: 负责创建
service, ingress resources, model server container and model agent container; - Ingress Gateway: 网关,路由外部/内部的请求;
在 Serverless 模式:
- Knative Service Controller
- Knative Activator
- Knative Autoscaler
数据平面
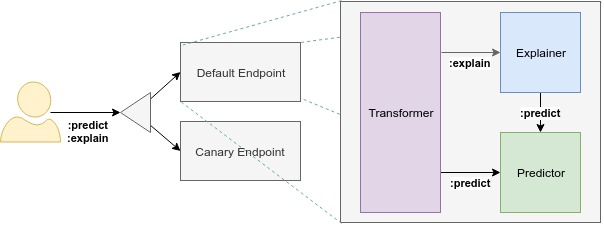
组件:
- Component:Each endpoint is composed of multiple components: "predictor", "explainer", and "transformer".
- Predictor:model server available at a network endpoint.
- Explainer: provides model explanations in addition to predictions.
- Transformer:define a pre and post processing step before the prediction and explanation workflows.
prediction v1 protocol
| API | Verb | Path | Payload |
|---|---|---|---|
| Readiness | GET | /v1/models/ | Response:{"name": , "ready": true/false} |
| Predict | POST | /v1/models/:predict | Request:{"instances": []} Response:{"predictions": []} |
| Explain | POST | /v1/models/:explain | Request:{"instances": []} Response:{"predictions": [], "explainations": []} |
prediction v2 protocol
The Predict Protocol, version 2 is a set of HTTP/REST and GRPC APIs for inference / prediction servers.
Health:
GET v2/health/live
GET v2/health/ready
GET v2/models/${MODEL_NAME}[/versions/${MODEL_VERSION}]/ready
Server Metadata:
GET v2
Model Metadata:
GET v2/models/${MODEL_NAME}[/versions/${MODEL_VERSION}]
Inference:
POST v2/models/${MODEL_NAME}[/versions/${MODEL_VERSION}]/infer
安装
k8s deployment
Raw Deployment 模式下不需要 Istio
- 通过管理
Ingress,控制路由,因此部署 Ingress-Nginx 即可。
创建 IngressClass
https://kserve.github.io/website/0.10/admin/kubernetes_deployment/
以 Nginx为例,参考 https://kubernetes.github.io/ingress-nginx/deploy/#quick-start,注意跟 K8s 的版本依赖
- 安装 ingress - nginx
helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace
- ingress - nginx 自带 IngressClass (不需要新增)
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.5.1
name: nginx
spec:
controller: k8s.io/ingress-nginx
安装 CertManager Yaml
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.11.0/cert-manager.yaml
安装Kserve Yaml
kubectl apply -f https://github.com/kserve/kserve/releases/download/v0.10.0/kserve.yaml
kubectl apply -f https://github.com/kserve/kserve/releases/download/v0.10.0/kserve-runtimes.yaml
修改 inferenceservice-config
部署模式为 RawDeployment
kubectl patch configmap/inferenceservice-config -n kserve --type=strategic -p '{"data": {"deploy": "{\"defaultDeploymentMode\": \"RawDeployment\"}"}}'
ingressClassName 为创建的 IngressClass
使用
模型支持
https://kserve.github.io/website/0.10/modelserving/v1beta1/serving_runtime/
单模型部署
模型服务运行时:针对不同框架 sklearn, tensorflow, pytorch, mlflow 都提供不同的CRD,运行不同的镜像;
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "flower-sample"
namespace: default
spec:
predictor:
model:
modelFormat:
name: tensorflow
storageUri: "s3://kfserving-examples/models/tensorflow/flowers"
# 修改运行时镜像的版本号
runtimeVersion: 2.7.1
kubectl apply 后通过 kubectl get isvc flower-example 查看状态
$ kubectl get isvc flower-sample
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
flower-sample http://flower-sample.default.example.com True 100
接口调用
MODEL_NAME=flower-sample
INPUT_PATH=@./input.json
SERVICE_HOSTNAME=$(kubectl get inferenceservice ${MODEL_NAME} -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v -H "Host: ${SERVICE_HOSTNAME}" http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predict -d $INPUT_PATH
其中输入数据格式为:
多模型部署
默认模式是'one model, one server' paradigm,当模型过多,会出现:
Compute resource limitation:cpu/gpu 的资源限制Maximum pods limitation- Kubelet has a maximum number of pods per node with the default limit set to 110,不建议超过 100;
Maximum IP address limitation.- Each pod in InferenceService needs an independent IP.
二进制数据
示例
基础
创建模型的 PV 和PVC
apiVersion: v1
kind: PersistentVolume
metadata:
name: kserve-demo-pv
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/home/liuzhiqiang/tensorflow-serving/serving/tensorflow_serving/servables/tensorflow/testdata"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- ${NODE_NAME}
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: kserve-demo-pvc
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
创建 InferenceService
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "tensorflow-kserve"
spec:
predictor:
model:
modelFormat:
name: tensorflow
storageUri: "pvc://kserve-demo-pvc/saved_model_half_plus_two_cpu"
查看部署状态
$ kubectl get isvc tensorflow-kserve
NAME URL READY ... AGE
tensorflow-pvc http://tensorflow-kserve-default.example.com True 2m15s
Ingress 配置
InferenceService的annotation会添加到 Ingress 的 annotation,因此通过对 InferenceService 添加注解,实现对 Nginx Ingress Controller的路由的配置定义。
模型存储
支持 S3, PVC 和 URI。
通过 webhook修改container,注入initConatainer(kserve/storage-initializer)
- 通过
emptyDir将模型数据在initContainer和container间传递。
Transformers
an
InferenceServicecomponent which does pre/post processing alongside with model inference
- transformer service calls to predictor service
对输入数据做预处理/后处理。
Kserve.Model定义三个 handlers,preprocess, predict 和 postprocess,顺序执行,且上个输出作为下个输入。
predict默认是通过获取predict_host进行 rest/grpc 调用;predict_host默认会作为参数传递,默认REST调用;
InferenceGraph
consist of many models to make a single prediction.
- e.g. a face recognition pipeline may need to first locate faces in a image, then compute the features of the faces to match records in a database
示例
https://kserve.github.io/website/0.10/modelserving/inference_graph/image_pipeline/#deploy-inferencegraph