基础
数据类型分类
结构化数据
结构化数据可以通过固有键值获取相应信息,且数据的格式固定。
- 表模型。
半结构化数据
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。
- json、html、xml等,树模型、图模型
非结构化数据
没有一个预先定义好的数据模型或者没有以一个预先定义的方式来组织。
- 文本、图像、音频、视频等。
读时模式和写时模式
"写时模式":数据在写入数据库时对照表模式进行检查,数据摄入(写入)速度慢,倾向于读效率;
- 要是所有记录都具有相同的结构,那么模式是记录并强制这种结构的有效机制。
"读时模式":在需要查询分析的时候再为数据设置schema进行验证(失败设置为NULL),底层存储不会在数据加载时进行验证。
- 存在许多不同类型的对象,将每种类型的对象放在自己的表中是不现实的;
- 数据的结构由外部系统决定。你无法控制外部系统且它随时可能变化;
DQL、DML、DDL、DCL的概念与区别
SQL(Structure Query Language)语言是数据库的核心语言。
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE 子句组成的查询块: SELECT <字段名表> FROM <表或视图名> WHERE <查询条件>
2 .数据操纵语言DML
数据操纵语言DML主要有三种形式: 1) 插入:INSERT 2) 更新:UPDATE 3) 删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER
DDL操作是隐性提交的!不能rollback
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如: 1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
3) COMMIT [WORK]:提交。
提交数据有三种类型:显式提交、隐式提交及自动提交。下面分别说明这三种类型。
(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT;
(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。
(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
数据字典
将属性值和主体分离,主体表只保存属性的的代码,这就是一种数据字典。
背景
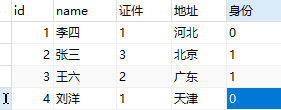
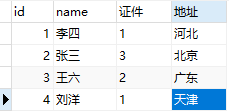
User表,User主体有很多属性,比如证件(身份证、居住证、港澳通行证...),地区(河北、河南、北京...)等,然后表建好了,数据也填进去了,项目代码也敲几万行。但是有一天,客户说这个“身份证”表述不够官方,要改成“居民身份证”比较好,作为这个项目开发人员,要把代码里和数据库中所有的“身份证”改成“居民身份证”,这工作量估计很让人抓狂。
两种形式
第一种:《主体表》里包含主体和属性代码,《属性表》里包含属性代码和属性Value,不同属性分别建表。
- 由于属性id是存储在主体表里的,属性的数量是不变的,而属性取值的数量可以是变化。
- 但是如果该主体的属性非常多的话,就需要建很多的属性表,在开发中还要设计很多属性类,那当想要取得一条主体的完全数据时,那将进行几十个表的联接(join)操作。性能耗损严重。
- 当属性的数量不多时,用第一种数据字典即可。
| <证件表> | <身份表> | |
|---|---|---|
 |
 |
 |
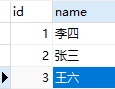
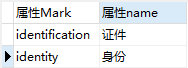
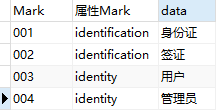
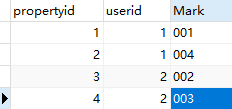
第二种:《主体表》里仅包含主体,《系统代码分类表》里存储属性标识和属性名称,《系统代码表》里包含所有属性代码、属性标识和属性Value,《属性表》是《主体》和《系统代码表》的关系表,包含属性id,主体id,属性代码。
- 由于这种设计方式属性和主题表是分开的,所以属性的数量是可变的,而属性取值的数量可以是变化的。
- 引入《系统代码分类表》和《系统代码表》,也解决了第一种设计方式的局限性。
| <系统代码分类表> | <系统代码表> | <属性表> | |
|---|---|---|---|
 |
 |
 |
 |
数仓
数据仓库中有这些概念:(通俗的讲,具体的概念可以看数据仓库的书)
主题:你要分析什么?如:某年某月某个地区的某种商品的销售量,这样的一个问题就是一个主体。
维度:从哪个角度来判断。如:时间角度(某年、某月……),地区(哪个国家、那个省……)
层次:维度的具体测量单位,类似于量长度时采用的哪种单位。如时间维度,年、季度、月就是不同的层次。
事实:就是你要分析主题的具体数字。如销售量、人均消费量、资产总数……
事实表与维度表
需要行和列来定位数值的,就是二维表;仅靠单行就能锁定全部信息的,就是一维表。
-
一维表称为源数据,特点是数据丰富详实,适合做流水账,方便存储,有利于做统计分析;
-
二维表称为展示数据,特点是明确直观,适合打印、汇报
事实表:表格里存储了能体现实际数据或详细数值,一般由维度编码和事实数据组成
维度表:表格里存放了具有独立属性和层次结构的数据,一般由维度编码和对应的维度说明(标签)组成
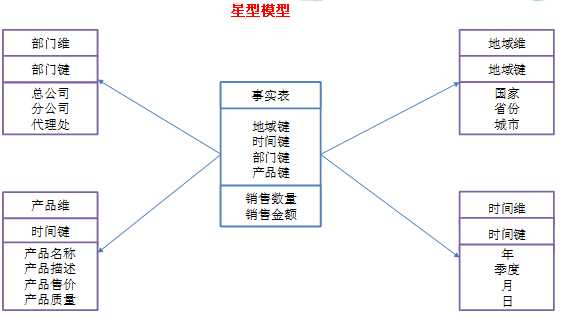
星型模型和雪花模型
星型模型:是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成
- 每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键;
-
事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据;
-
一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,所以数据有一定的冗余。
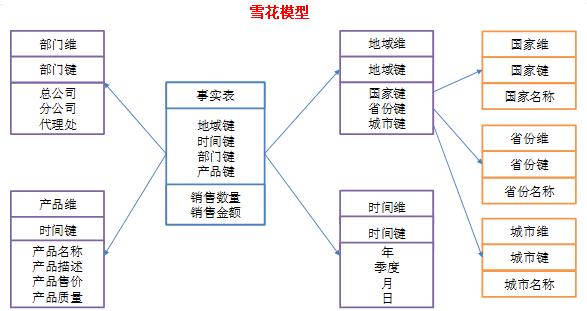
雪花型模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
- 原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域;
- 减少数据存储量以及联合较小的维表来改善查询性能,雪花型结构去除了数据冗余。
对比:
- 查询性能:在OLTP-DW环节,由于雪花型要做多个表联接,性能会低于星型架构;但从DW-OLAP环节,由于雪花型架构更有利于度量值的聚合,因此性能要高于星型架构。
- 模型复杂度:星型架构更简单方便处理
- 层次结构:雪花型架构更加贴近OLTP系统的结构,比较符合业务逻辑,层次比较清晰。
- 存储角度:雪花型架构具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型架构会产生数据冗余。
根据项目经验,一般建议使用星型模型。因为在实际项目中,往往最关注的是查询性能问题。
术语
- 数据加载层:ETL(Extract-Transform-Load)
- 数据运营层:ODS(Operational Data Store)
-
数据仓库层:DW(Data Warehouse)
-
数据明细层:DWD(Data Warehouse Detail)
- 数据中间层:DWM(Data WareHouse Middle)
- 数据服务层:DWS(Data WareHouse Service)
- 数据应用层:APP(Application)
- 维表层:DIM(Dimension)