Graphx
Spark for graphs and graph-parallel computation.
基于 RDD 封装 Graph 抽象(a directed multigraph with properties attached to each vertex and edge)。
- 有向图:边存在方向;
- 多重图:两个顶点间存在多条边;
- 属性图:边和顶点都具备属性;
属性图
顶点:通过唯一的64位long型标识(VertexId),不对顶点标识符施加任何排序约束。;
注:当顶点和边类型是基本数据类型(如int、double)时,通过将它们存储在专用数组中来减少内存占用。
Graph 除了 vertices 和 edges,定义 triplets 视图 (RDD[EdgeTriplet[VD, ED]])

算子
Graph 和 GraphOps (隐式转换)类中。
/** Summary of the functionality in the property graph */
class Graph[VD, ED] {
// Information about the Graph ===================================================================
val numEdges: Long
val numVertices: Long
val inDegrees: VertexRDD[Int]
val outDegrees: VertexRDD[Int]
val degrees: VertexRDD[Int]
// Views of the graph as collections =============================================================
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED]
val triplets: RDD[EdgeTriplet[VD, ED]]
// Functions for caching graphs ==================================================================
def persist(newLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED]
def cache(): Graph[VD, ED]
def unpersistVertices(blocking: Boolean = false): Graph[VD, ED]
// Change the partitioning heuristic ============================================================
def partitionBy(partitionStrategy: PartitionStrategy): Graph[VD, ED]
// Transform vertex and edge attributes ==========================================================
def mapVertices[VD2](map: (VertexId, VD) => VD2): Graph[VD2, ED]
def mapEdges[ED2](map: Edge[ED] => ED2): Graph[VD, ED2]
def mapEdges[ED2](map: (PartitionID, Iterator[Edge[ED]]) => Iterator[ED2]): Graph[VD, ED2]
def mapTriplets[ED2](map: EdgeTriplet[VD, ED] => ED2): Graph[VD, ED2]
def mapTriplets[ED2](map: (PartitionID, Iterator[EdgeTriplet[VD, ED]]) => Iterator[ED2])
: Graph[VD, ED2]
// Modify the graph structure ====================================================================
def reverse: Graph[VD, ED]
def subgraph(
epred: EdgeTriplet[VD,ED] => Boolean = (x => true),
vpred: (VertexId, VD) => Boolean = ((v, d) => true))
: Graph[VD, ED]
def mask[VD2, ED2](other: Graph[VD2, ED2]): Graph[VD, ED]
def groupEdges(merge: (ED, ED) => ED): Graph[VD, ED]
// Join RDDs with the graph ======================================================================
def joinVertices[U](table: RDD[(VertexId, U)])(mapFunc: (VertexId, VD, U) => VD): Graph[VD, ED]
def outerJoinVertices[U, VD2](other: RDD[(VertexId, U)])
(mapFunc: (VertexId, VD, Option[U]) => VD2)
: Graph[VD2, ED]
// Aggregate information about adjacent triplets =================================================
def collectNeighborIds(edgeDirection: EdgeDirection): VertexRDD[Array[VertexId]]
def collectNeighbors(edgeDirection: EdgeDirection): VertexRDD[Array[(VertexId, VD)]]
def aggregateMessages[Msg: ClassTag](
sendMsg: EdgeContext[VD, ED, Msg] => Unit,
mergeMsg: (Msg, Msg) => Msg,
tripletFields: TripletFields = TripletFields.All)
: VertexRDD[A]
// Iterative graph-parallel computation ==========================================================
def pregel[A](initialMsg: A, maxIterations: Int, activeDirection: EdgeDirection)(
vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
// Basic graph algorithms ========================================================================
def pageRank(tol: Double, resetProb: Double = 0.15): Graph[Double, Double]
def connectedComponents(): Graph[VertexId, ED]
def triangleCount(): Graph[Int, ED]
def stronglyConnectedComponents(numIter: Int): Graph[VertexId, ED]
}
示例
示例图表示:
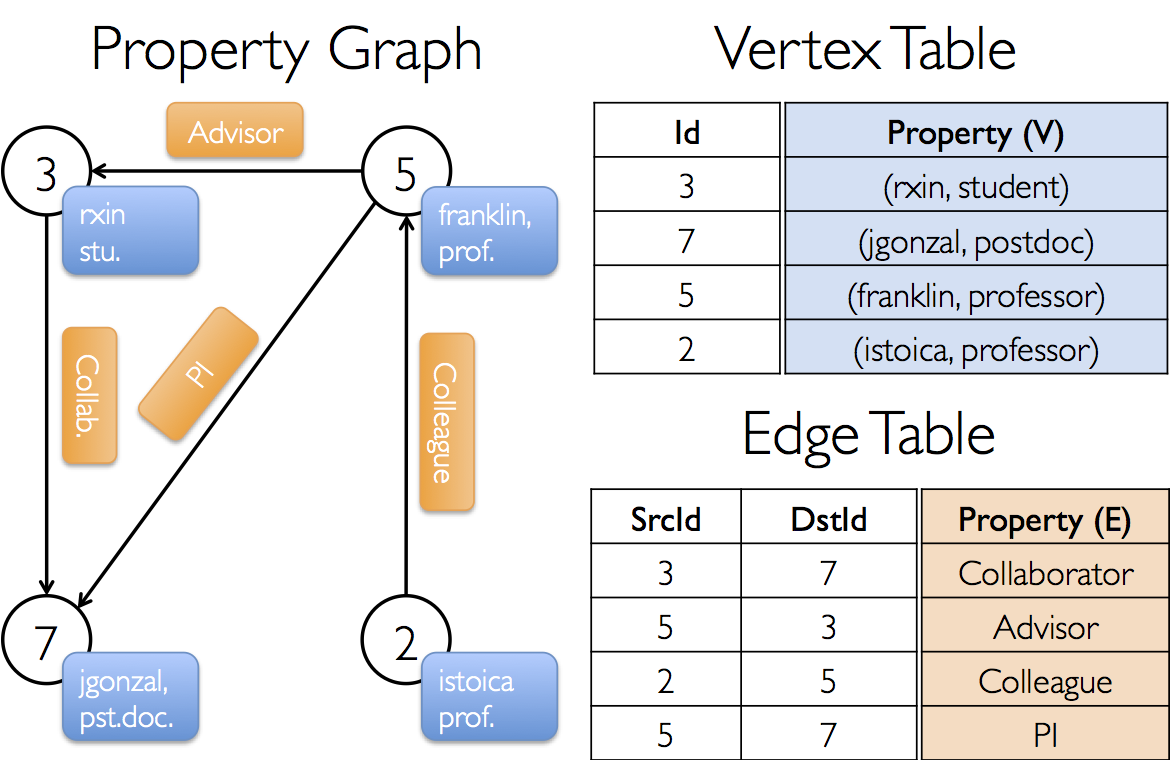
构造
// Assume the SparkContext has already been constructed
val sc: SparkContext
// Create an RDD for the vertices
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Seq((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Seq(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)