Spark Yarn
架构
Spark 相关概念:
- Driver:和ClusterManager通信,进行资源申请、任务分配并监督其运行状况等。
- ClusterManager:这里指YARN。
- DAGScheduler:把spark作业转换成Stage的DAG图。
- TaskScheduler:把Task分配给具体的Executor。
YARN相关概念:
- ResourceManager:负责整个集群的资源管理和分配。
- ApplicationMaster:YARN中每个Application对应一个AM进程,负责与RM协商获取资源,获取资源后告诉NodeManager为其分配并启动Container。
- NodeManager:每个节点的资源和任务管理器,负责启动/停止Container,并监视资源使用情况。
- Container:YARN中的抽象资源。
Yarn-Client
client模式下,driver运行在client的进程中。(YarnClientClusterScheduler => YarnClusterScheduler)
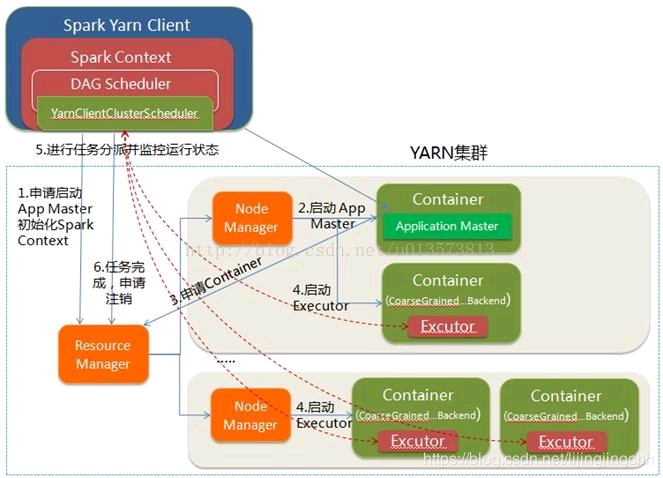
- Client 向 RM 申请启动 AM。同时 driver 初始化Spark Context,DAGScheduler、YarnClusterScheduler等;
- RM 收到请求,在集群中选择一个 NM 分配第一个Container,作为 AM。AM不运行 SparkContext,只是跟Client 通信进行资源申请;
- Client 与 AM 进行连接,向 RM 注册,根据任务信息通过 AM 向 RM 申请资源;
- AM 申请到资源 Container 后,与对应的 NM 进行通信,要求它在获取的Container中启动CoarseGrained Backend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
- client中的 SparkContext 分配 Task 给 CoarseGrainedExecutorBackend 执行,CoarseGrainedExecutorBackend 运行 Task 并向 Driver 汇报运行的状态和进度,以让 Client 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
Yarn-Cluster
与 client 模式的区别:
- Driver 进程运行在 AM 中,与 RM 进行资源的申请;
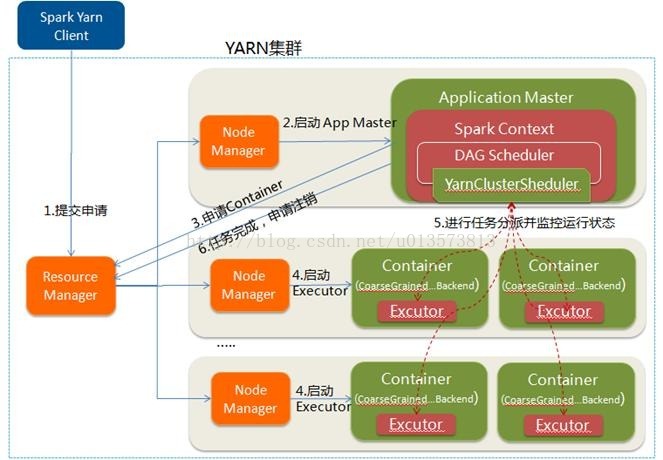
Yarn Cluster Executor 申请
源码类:
YarnAllocator
流程
1、ApplicationMaster中会创建YarnAllocator,主线程会首先调用一次YarnAllocator.allocateResources()进行资源请求分配,接下来会创建reportThread线程,该线程会循环不断的调用YarnAllocator.allocateResources(),所有的操作都在allocateResources()中;
2、YarnAllocator首先会创建ContainerRequest,ContainerRequest的请求数=总的executor数,对于固定executor数量(即没有配置executor动态分配)的application,ContainerRequest请求的container是任意节点的,即完全由ResourceManager随机分配。如果Executor是动态分配的,那么会尽可能按照最大化数据本地策略请求container;
3、amClient 向 ResourceManager提交资源请求,再调用 allocate 获取RM给分配的containers;
4、对分配到的containers进行筛选,匹配之前的ContainerRequest,满足请求的container才会被认为是可用的。一般情况下,ContainerRequest是任意节点,RM分配的container都能满足需求。某些情况下container可能不满足,那么会把不满足的container资源释放掉;
5、对筛选完的container,每个container被封装为ExecutorRunnable,由一个独立的线程来启动。具体是创建ContainerLaunchContext,由nmClient(NodeManager客户端)负责启动Container(入口类是 YarnCoarseGrainedExecutorBackend);
container 筛选的逻辑:
1、首先根据接收到的container的 host在amClient中进行的匹配
2、从1中剩余的container中再次进行rack的匹配
3、同1、2类似,从2中剩余的container对任意位置的ContainerRequest进行匹配
4、经过层层匹配筛选后,可用的container都添加到containerToUse列表中,不满足请求的container资源将被释放
5、调用runAllocatedContainers()方法在container上启动Executor进程
本地性
对于静态 Executor:
- 申请 Executor 时,不清楚需要哪些数据的,因此申请时没有本地性可言;
对于动态 Executor(dynamic==true):
- 根据 Host 上的 Task 信息,申请Container,具备本地性;
Spark 在运行时,可以再申请 Executors,SparkContext::requestExecutors
Spark 在调度 Task 时,会考虑数据的本地性(TODO)。
配置
1)配置HADOOP_CONF_DIR和YARN_CONF_DIR环境变量;
- 直接通过 new SparkConf(),需要将其加入CLASSPATH中;
2)Spark Runtime jars:spark.yarn.archive 或者 spark.yarn.jars
GPU
Spark 向 Yarn 申请资源,通过配置的discoverScript,发现Container(driver/executor)的GPU卡;
Spark的Scheduler会根据executor的GPU资源信息,分配Task作业,并将资源信息传入Task;
Spark分区(Task)可以通过TaskContext获取Task使用的资源信息(比如Task可以使用的GPU卡号);
自定义资源申请
如申请自定义资源 dcu:
--conf spark.executor.resource.dcu.discoveryScript=/opt/hc-software/spark/bin/getDcusResources.sh
- 用于executor中配置dcu获取脚本
--conf spark.executor.resource.dcu.amount=2
- 用于配置spark侧的资源名称及其数量
在Yarn上时,注意:--conf spark.yarn.executor.resource.dcu.amount=2
- 用于配置spark在yarn侧的资源名称及其数量
节点标签(分区)
可以通过Yarn的队列跟分区一对一绑定,设置队列的默认分区标签,避免 Spark 侧的配置。
spark.yarn.am.nodeLabelExpression
spark.yarn.executor.nodeLabelExpression
节点属性(Placement Constraint)
Spark 3.4 当前不支持 Placement Constraint。